Advent of Code in Production, Day 6: Operating Environment
Let's talk distributed systems! Getting into the details of how we could build a whole system to support Santa's elves, instead of a bunch of scripts.


This post is part of a system design exercise to build software tools to assist Santa's elves in their star fruit gathering expeditions. It's an alternative take on the Advent of Code community event. Up to this point, we haven't known enough about our operational constraints to do more than some data and domain modeling. After today's challenge, we have plenty to work with.
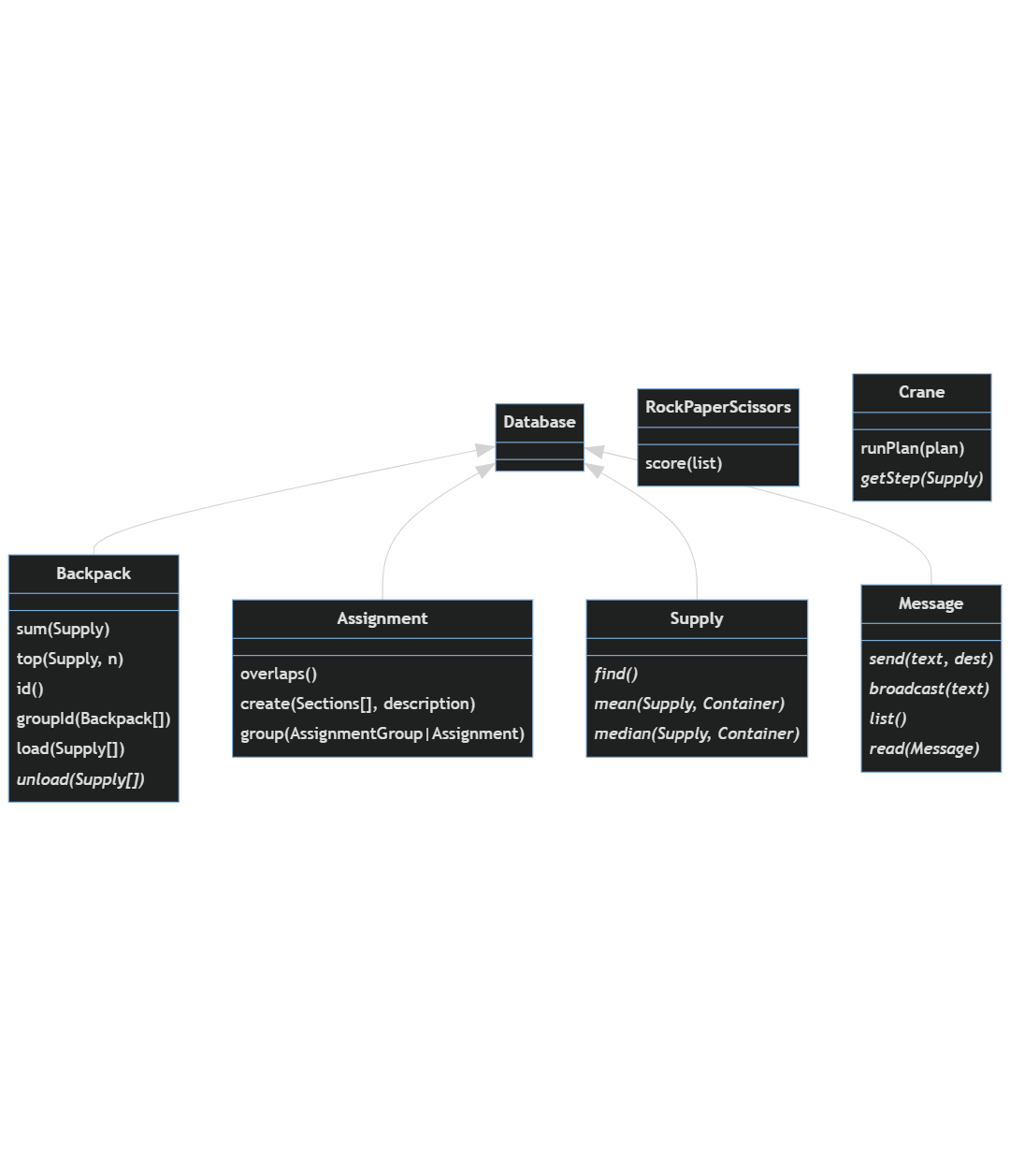
You may be wondering what happened to day 5? I think it's probably not interesting to cover every single day in detail in this series. At this point, the project has some established patterns, and many of the daily challenges will just extend those patterns to new features, or even be mostly irrelevant to the system. From here on, I'll likely give quick summaries of how the system has grown, and mainly focus on things that stand out for some reason. On day 5 we were asked to help with analyzing a crane operation plan to predict the final result so that the elves can unload it. I doubt this is useful to add to the data model, but we can build a service to do this analysis on-demand. Some of the obvious enhancements to this would include modifying the prediction based on removing containers mid-plan, and/or making predictions of when during the unloading operation a kind of container will be on top and ready to unload. I'm sure these things are a big help to the elves, but I'm more interested in what we learn on day 6. So, here's where we do that update before we get into the new stuff.
Infrastructure
Up to this point, I've described things in some very generic terms: service, database, system, etc. This has been on purpose. We didn't know what our operational constraints would be, so it was impossible to design for them. But now we know a lot more.
It seems a lot of work is going to happen out in the field. That's not a surprise, but we know more about what that actually means for our system. The elves rely heavily on some mobile devices that they call communicators. Those communicators are general purpose computers that are easy to program and have no problem running our software and development tooling. We can expect they'll spend a lot of time running on battery power, and based on the network protocols they use, it seems that at least sometimes bandwidth will be extremely limited. In fact, the way those protocols are structured puts me in mind of protobufs, and I think it will make sense to use protobuf based gRPC as the basis of our rpc design. The protocol doesn't seem to be connection oriented. I can imagine that might make sense for certain point to point communication, or if conditions produce high latency or such unreliable network environments that connections can't reliably be established or maintained. It might also be to preserve battery by saving on radio activations used for connection handshakes and other overhead.
Basically, all this makes me think we need to plan for networks that are at least sometimes only intermittently available, and finite battery power. Communicators probably spend a lot of time in a text only terminal mode. In fact, it's not obvious if they even support other modes. I'm guessing that this has leaked into the processes, communication, and data formats the elves use, which explains a lot about the input data we've seen so far.
So, what does that mean for our system design? A lot. To start, I'm not sure we can use a client-server design. At least not universally. Communicators can't rely on remote data or processing; it all has to be available locally. The service we're building probably looks less like a web server and UI, and more like a distributed system of peers. It probably consists of a daemon and CLI tool, and our stack should reflect that. A language that's been optimized for mobile applications might be a good idea. Maybe Kotlin? And we don't have a database so much as many databases. Or, maybe we should think of it as a sort of distributed database?
Databases
One of our largest challenges here is how to keep data both locally available and globally consistent, when the local databases will often not have any connection to each other. The elves have set up a base camp and are preparing to set up other camp locations. I presume that these camps will have relatively reliable infrastructure. Reliable enough, anyway. But they're also going to do their most important work away from camp. I imagine they'll need access to data like maps, inventories, and survey plans while out. Most likely they'll also need to record information that needs to be relayed to the rest of the system whenever they next have the opportunity. The question is: do we want the application to handle that synchronization, or should it be done by the database itself?
One thing to point out: We started out using PostgresQL. I still think that was a reasonable decision based on what we knew at the time. But now we know more, and a different database is going to serve us better. I made a point of constraining our choices to SQL databases. That's absolutely not going to eliminate the difficulty from migrating, but it will mean we probably don't need to change any of our access patterns or data models. So, we'll find the places where we were using PL/SQL or pg functions that don't exist in the new database and replace them with something else. It's only been 5 days, so I expect that will be pretty doable.
🥇 Dolt
I think, for this scenario, Dolt is our best bet. It's a distributed SQL DBMS but distributed in the same way that git is distributed. In fact, it uses quite a lot of git semantics. This way, each communicator in the system can have a fully local copy of the database, and they can commit, merge, and share their changes as the situation permits. Dolt will provide tools to resolve conflicts where data was changed by multiple elves while out of contact with each other. In the very long term, it's possible that we would be better off handling this ourselves, rather than depending on a vendor database to do it. But, since we now have less than 3 weeks until Christmas, I'm going to opt for an off-the-shelf solution. And bonus: Dolt can be used as an embedded database, which means our services can have more control over its impact on power consumption.
My biggest concern at this stage is how much storage could potentially be required by retaining multiple versions of tables. We know storage on the communicators is finite, but not how much is actually there (reading ahead one day tells us it's 70 million something, but not the unit). Still, I'm going to base an assumption on one of the conceits of the challenge: that we can easily run our software development toolchain of choice on these communicators. So, while we're not going to be able to run off to S3 for help anytime soon (I suspect the nearest AWS zone is in Stockholm), we don't need to be panicked about storage, either.
🥈 InterBase
InterBase is an efficient, high performance, embeddable SQL database. I think this would be the first-choice database if we had decided to make the SFTools application itself responsible for managing the data sync-and-merge that our system will probably require.
🥉 DQLite
DQLite is a more conventional distributed database that is also embeddable. It's made by Canonical and built on top of SQLite. The problem for our use case is that the conventional way for a distributed database to work is by authority or consensus mechanisms. I'm skeptical that will work well for us in this scenario where we expect it will often be true that the majority of members in the distributed database network will be unavailable. I think there's a lot of risk that we would end up with multiple minority consensuses and unintentionally fork the database. That's a failure mode I want to avoid. If the network is more reliable and available across the full system than I'm assuming, then this becomes a much more compelling option.
Tech Stack
You can view our communicators almost like they're embedded devices. I think they have more computing power than that term would normally imply, but it's a similar dynamic. They definitely have limited resources, including I/O features. I think the two most limited resources will be battery and network. So, we want to use a language that's well suited to building things like headless daemons and CLI apps, as well as being efficient and good at managing power consumption.
🥇 Golang
I'm going to choose Golang, because I think it checks those boxes. It could easily have been Rust, instead. But it's my decision and I want a garbage collector. I'm also doing these challenges in the conventional way in Golang, as a learning exercise, so that's a factor.
🥈 Rust
Just like Golang, Rust is a high-performance language that's well suited to the kind of system we're building. Also, like Golang, it doesn't require that we ship a runtime on our communicators. We can compile these programs, distribute them, and be reasonably confident that they'll keep working for quite a while. TBH, in this case, I think both languages are very good options and it's as much a question of taste and familiarity as anything else.
🥉 Kotlin or Swift
In my view, the other good options here are Kotlin and Swift; languages that have grown up powering smart phones. I would expect them to do very well on the power management front. And I think they would do fine with the headless parts of the system. But I'm not sure how they would hold up working with text-only UIs. And they both depend on having a runtime available, which makes distribution and deployment a much more complicated affair. Doing that without an app store is not a challenge I'm interested in taking on.
System Design
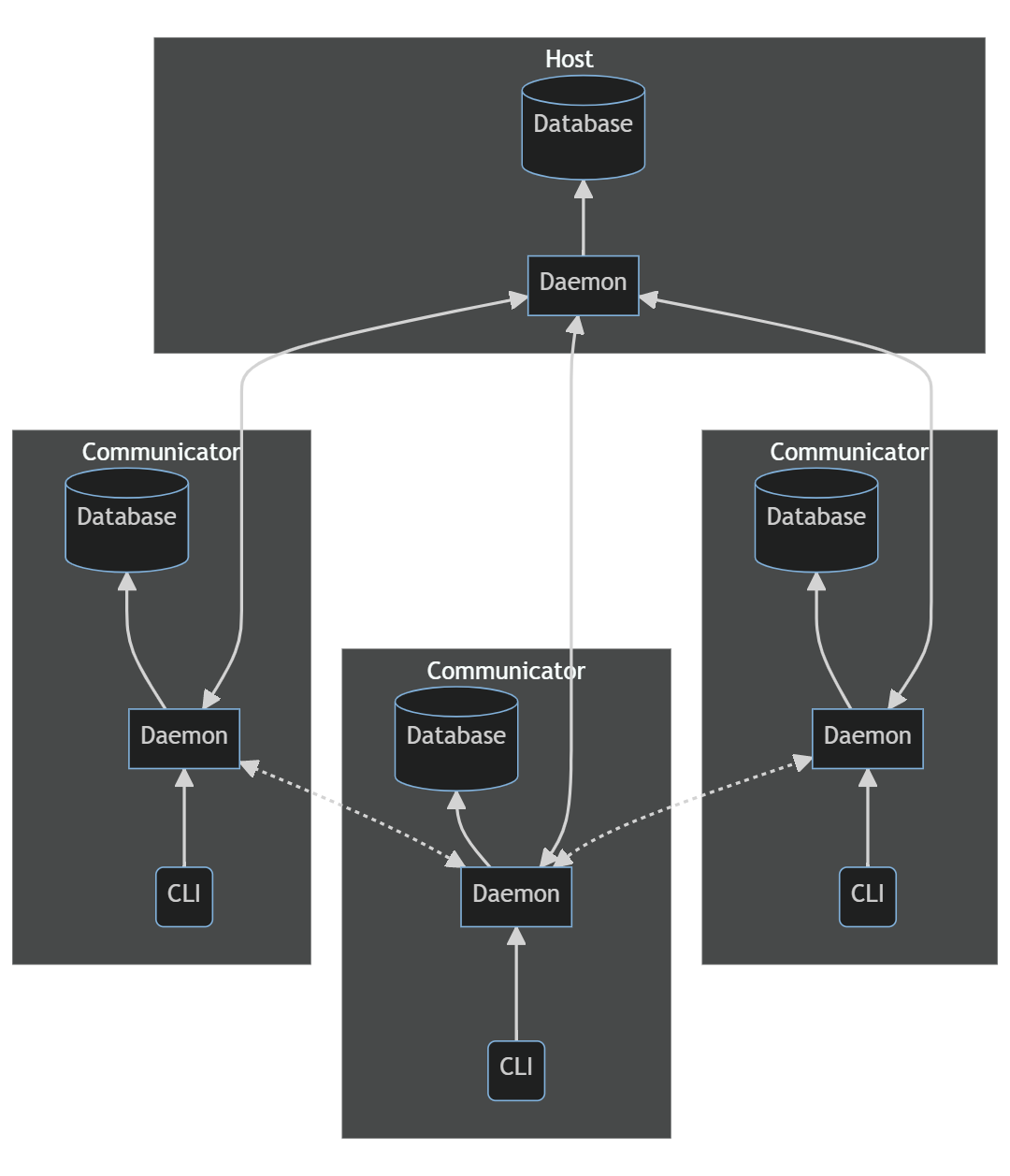
Alright, we have a lot of foundational pieces settled. We're going to build a distributed system of peers in Golang with a distributed Dolt data base, using a CLI/daemon arrangement. I think we can also have some of these instances at camps running in a host mode, and they can serve as authoritative data sources, so we don't need to worry about consensus. To conserve power, RPCs will use protobufs for serialization; using gRPC when reliable TCP connections are feasible, and plain UDP when they aren't. That will be up to the operators to determine. I think I'll call these two modes Stable and Burst, because I don't think it's reasonable to expect all of our elves to know what the difference is between TCP and UDP transports and why they would choose one or the other.
One thing I'm not sure about is how we should organize communicating between peers. We could do it either in a CLI/remote daemon way, or a local daemon/remote daemon way. I think CLI would be easier to implement, and I want to do that. The problem is that it might not work well for one particular scenario that I expect to be pretty important. If communicators in the field get only intermittent network connections, then we might need to opportunistically send messages as we're able. I think that would be best done by letting the daemon work in a kind of store-and-forward pattern. I'm of the opinion that all communication systems are actually safety critical and so they should prioritize reliability above most other concerns. So, that's what we'll do. And with that, I think it's time to draw some diagrams.
P.S.
As before, if you'd like to follow along with the regular challenges, you can do that.
Cover photo by Meruyert Gonullu